
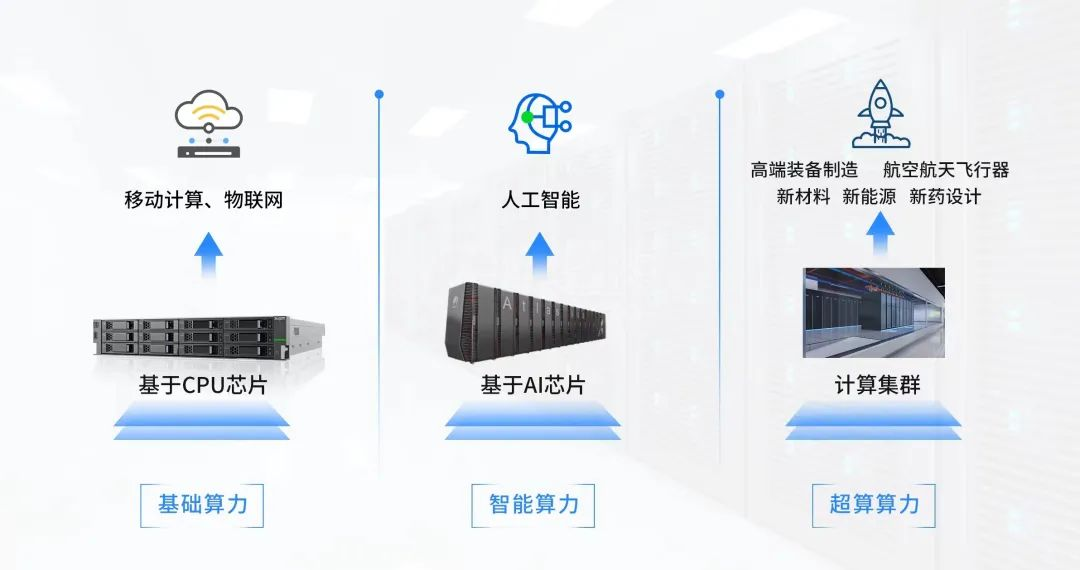
开篇场景:建一座“数字工厂”
假设你要建一家汽车工厂:
需要多少工人?
每个工人每小时能装多少零件?
一天能生产多少辆车?
算力中心也是这样:它的“工人”是 CPU/GPU/NPU,每个工人每秒能完成多少计算,决定了整座工厂的产能。
今天我们就来揭开:一座算力中心的算力,究竟是怎么算出来的。
一、算力的核心公式
一座算力中心的计算能力,可以简单表示为:
总算力 = 单个硬件算力 × 硬件数量 × 协同效率
其中:
单个硬件算力:CPU/GPU/NPU 的 FLOPS/TOPS 指标。
硬件数量:机架规模、GPU张数、CPU核数。
协同效率:存储带宽、网络延迟、调度算法。
这就像:工人再多,如果运输不畅、沟通效率低,也生产不出多少车。
算力(CP,ComputationaPower)即数据中心的计算能力。指数据中心的服务器通过对数据进行处理后实现结果输出的一种能力,是衡量数据中心计算能力的一个综合指标,数值越大代表综合计算能力越强。算力应是数据中心内所有服务器的算力加和。

二、从单卡到集群:逐层拆解
单个 GPU 的算力
例如 NVIDIA A100:单精度约 19.5 TFLOPS。
机架级算力
一台服务器常配 8 张 A100:
算力 ≈ 8 × 19.5 TFLOPS = 156 TFLOPS。
机房级算力
如果有 1,000 台这样的服务器:
算力 ≈ 156 × 1,000 = 156,000 TFLOPS = 156 PFLOPS。
算力中心级算力
进一步扩展到数万台服务器,进入 E级超算(Exascale)。
👉 你会发现,算力不是单卡炫耀,而是 规模化 × 协同化 的产物。
算力(CP)的核心要素包括通用算力(即CP-Nomal,简写CPN)和智能算力(即CP-Tuto,简写CPT)。通用算力是指数据中心服务器仅包含CPU的算力。智能算力是指数据中心服务器不仅包含CPU,也包含GPU或AI芯片的算力。因此数据中心的算力(CP):

三、存储与网络的加权作用
很多人以为算力只看 GPU 数量,其实不对。
存储带宽:AI训练时,数据能不能及时“喂”到显卡?
网络延迟:万张 GPU 之间能不能高速通信?
任务调度:能否把任务合理分配给成千上万节点?
举个比喻:
算力中心就像高速工厂流水线;
如果数据像原料运不进来,算力就“饿死”;
如果网络通信慢,就像工人喊话要靠吼,效率会大打折扣。
因此,综合算力往往是 计算 + 存储 + 网络 的合力,而不是单一 FLOPS。
算力(CP)最常用的单位是FLOPS(Floatimng point OperationsPer Secnd,每秒浮点运算次数)。事实上,FLOPS已成为各种设施(如计算机、超算机、服务器等)衡量计算性能的代名词。FLOPS是一个基本单位,它的更大的数值单位有K(千)、M(兆)、G(吉)、T(太)、P(拍)、E(艾)。
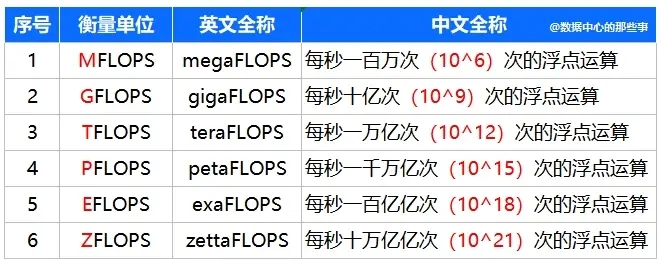
算力精度不同,实际算力水平差别巨大。如果因此衡量算力水平,单一采用运算次数指标是不够的,还应考虑算力精度。
根据参与运算数据精度的不同,可把算力分为:双精度算力(64位,FP64)、单精度算力(32位,FP32)、半精度算力(16位,FP16)及整型算力(INT8、INT4)。数字位数越高,意味着精度越高、可支持的运算复杂程度越高、适配应用场景越广。
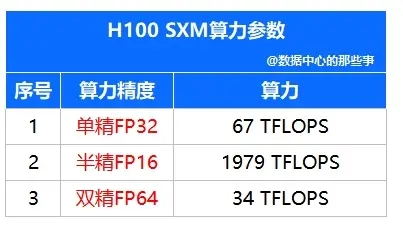
但是一般情况下,算力规模测算时统一折算为单精度浮点数(FP32)算力进行统计。

四、一个真实算力计算案例
我们来算一笔“ChatGPT训练账单”:
OpenAI 训练 GPT-3 时,使用约 10,000 张 NVIDIA V100 GPU。
单张 V100:约 14 TFLOPS(FP32)。
总算力 ≈ 14 × 10,000 = 140,000 TFLOPS = 140 PFLOPS。
如果用电量折算:
一张 V100 功耗约 300W;
10,000 张功耗 = 3 MW;
训练几周,总电费超过千万人民币。
👉 这就是为什么大家说 AI 是“烧钱机器”。
算力是通过数据中心内所有服务器的算力加和来统计的。如果我们仅知道IT电力容量时,怎么去估算数据中心(智算中心)的算力呢?
首先我们应选定一款AI服务器,查看它的用电功率。以H100 GPU 服务器为例:CPU耗电约300W*2,内存16根耗电约 250W,硬盘6块盘约200W,风扇耗电约150W,H100GPU卡耗电约700W*8,按理论计算最大耗电量约为6800W。而以H100模组整机服务器满配的情况下,单台约功率约10kW。例如数据中心的IT总容量为8000kW,计算服务器台数:

从上公式,计算出本数据中心可布置800台H100 GPU 服务器。然后计算服务器的GPU算力。
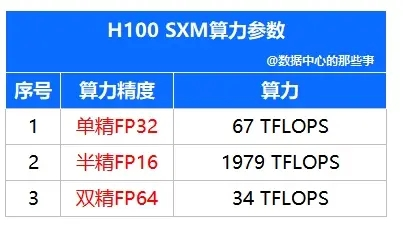
通过上表查出,H100 GPU单卡算力为67TFLOPS,单台服务器共有8张GPU卡。在忽略CPU算力的情况下,可计算出数据中心中心的算力规模为:

由上公式,可以算出428,800TFLOPS(半精度FP32),即428.8PFLOPS(半精度FP32)。一般情况下,建议在后面加上算力精度,避免产生歧义。
五、算力计算的三大误区
只看 GPU 数量:忽视存储与网络,结果“跑不满”。
只看峰值算力:忽略能效,实际利用率可能 <50%。
只看硬件指标:忽略算法优化,很多 AI 框架能让同样硬件跑得更快。
算效(CE,ComputationalEmciency)是指数据中心算力与功率的比值,即“数据中心每瓦功率所产生的算力”,是同时考虑数据中心计算性能与功率的种效率。数值越大,代表单位功率的算力越强,效能越高。若CP为以单精度浮点数(FP32)的数据中心的算力,PC为数据中心IT设备的整体功率,其单位为瓦(W),则算效CE的计算公式为:

再以上面的数据中心为例,代入算力428,800TFLOPS(半精度FP32)与IT总容量8000kW进行计算:

计算出数据中心的算效为5350FLOPS/W。
六、结尾升华
算力的计算,不只是“加GPU”这么简单,而是一门综合工程:
像建工厂:工人数量(GPU)、流水线(存储)、运输车(网络)、管理制度(调度)。
像运营城市:电力、道路、通信都要协同。
未来的算力中心,不仅比拼谁的 GPU 多,更比拼谁能 高效调度、绿色节能、智能协同。
👉 下一讲,我们将深入显卡世界:GPU 为什么成了算力中心的核心武器?