
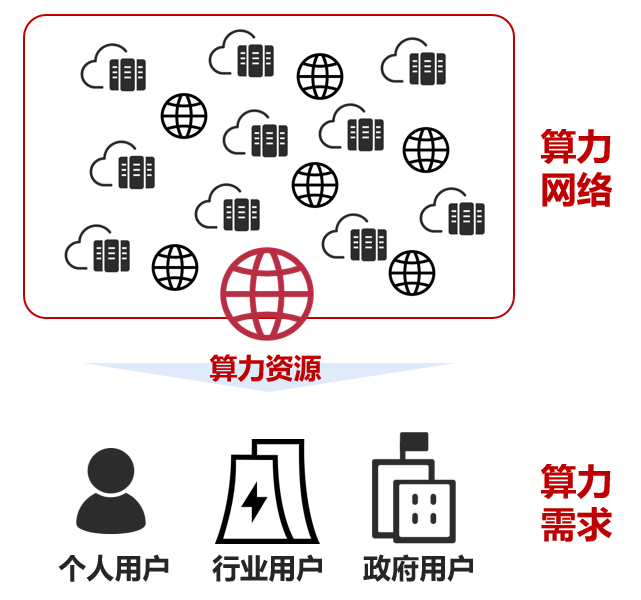
开篇场景:一座“数字工厂”的流水线
如果把算力中心比作一座超级工厂:
计算单元 就像工厂里的工人,负责核心生产;
存储系统 就像仓库,提供原料和半成品;
网络系统 就像运输管道,把原料和成品在各环节之间快速流转。
三者缺一不可,任何一环掉链子,整个工厂都会瘫痪。
这,就是算力中心的三大基石架构。
一、计算层:CPU + GPU + NPU 的协奏曲
CPU(大脑/指挥官)
优点:逻辑处理强,能调度全局。
缺点:并行能力不足。
作用:调度任务、控制流程、做预处理。
GPU(主力军/士兵)
优点:上千个核心并行,擅长矩阵运算。
缺点:不擅长复杂逻辑。
作用:AI训练、科学计算、渲染。
NPU/TPU(特种兵)
优点:为AI推理优化,能效比高。
缺点:通用性不足。
作用:AI推理、边缘计算、语音/图像识别。
计算层是算力中心的“发动机”。
二、存储层:数据就是“燃料”
高速缓存(Cache/内存)
保证计算单元不“饿肚子”。
数据能否快速送达,直接决定GPU是否能跑满。
分布式存储
把成千上万块硬盘组织成一个“超级仓库”。
HDFS、Ceph 等方案常见。
冷热分层
热数据放在SSD(快但贵);
冷数据放在HDD(便宜但慢)。
存储层是算力中心的“粮仓”。
三、网络层:算力的“血管”
高速互联
GPU之间要高速通信(如深度学习中的梯度同步)。
技术:InfiniBand、RDMA、CXL。
数据传输
东数西算工程需要跨省算力调度。
技术:骨干光纤网络、低时延传输协议。
调度系统
Kubernetes、Slurm、云原生算力调度平台。
决定资源如何分配、如何避免拥塞。
网络层是算力中心的“交通网”。
四、三者协同的案例:AI大模型训练
以 GPT 模型训练为例:
计算层:上万张 GPU 并行处理矩阵计算;
存储层:TB/PB级训练数据需要随时读取;
网络层:跨GPU节点要快速交换参数(AllReduce操作)。
如果存储不够快 → GPU闲置 → 算力浪费;
如果网络延迟高 → 同步失败 → 模型训练崩溃。
这就是为什么 算力中心拼的不是单一硬件,而是全栈协同。
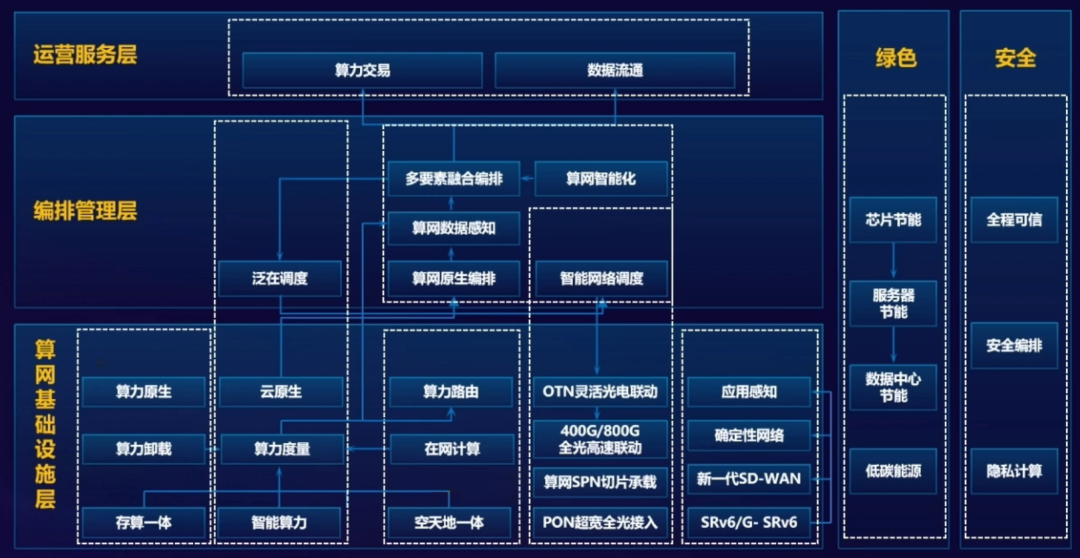
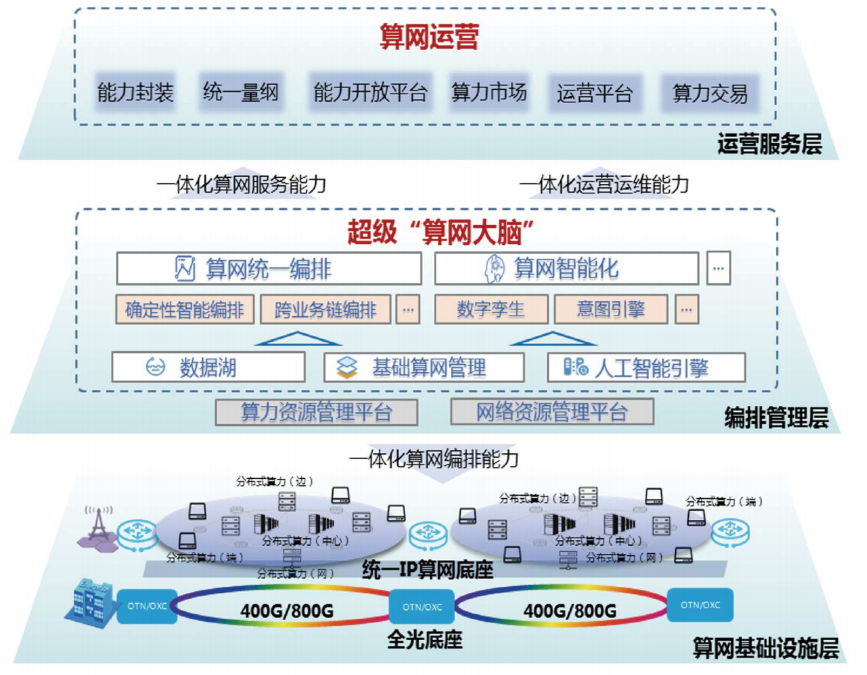
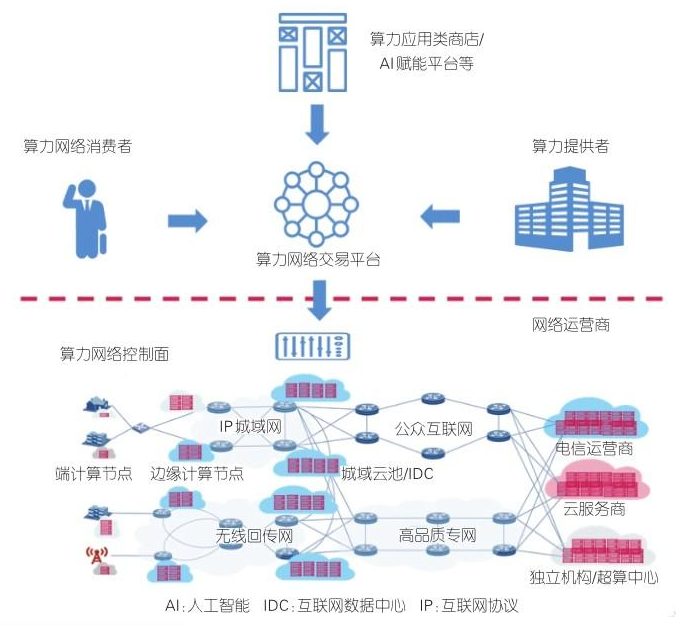
中国联通算力网络架构
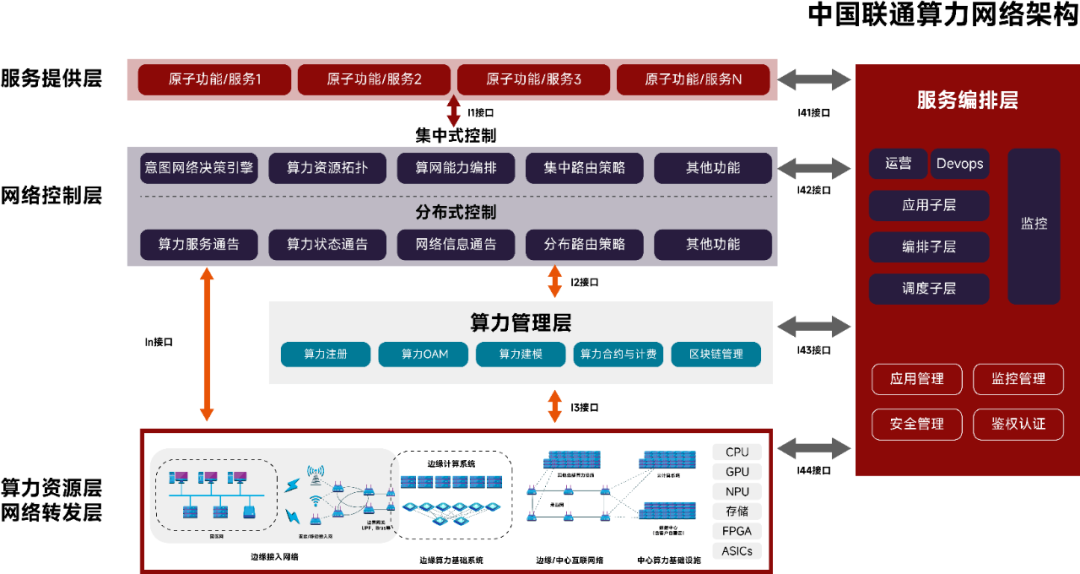
中国电信云网融合目标技术架构
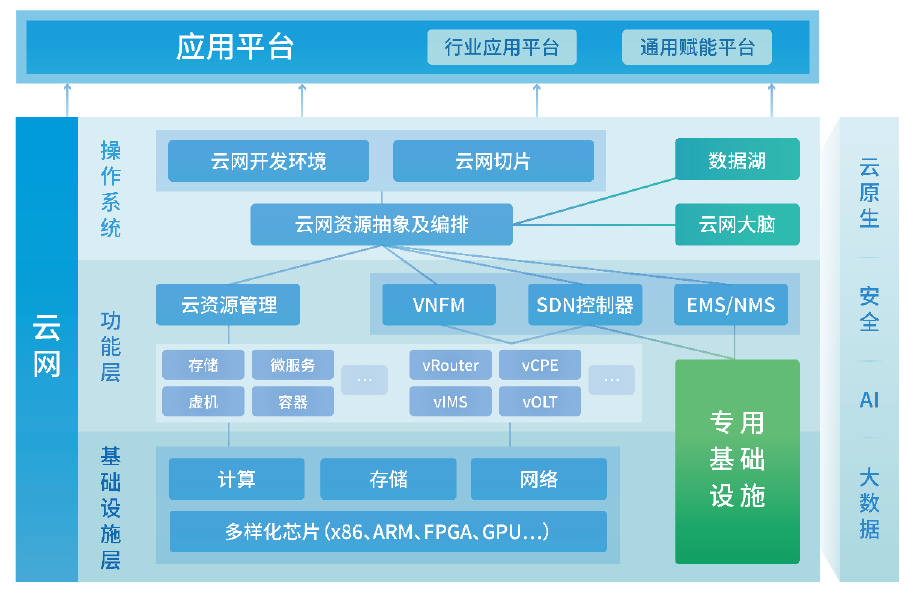
华为架构
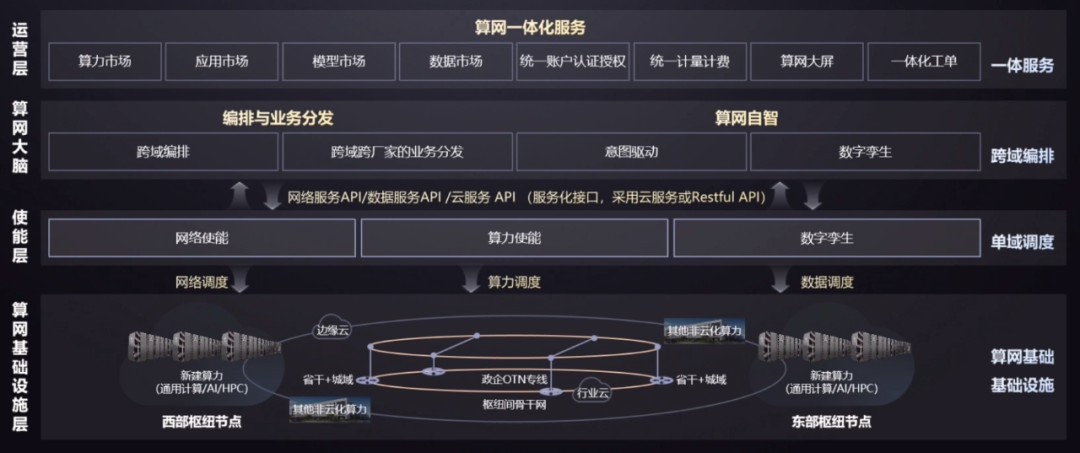
分层示意图
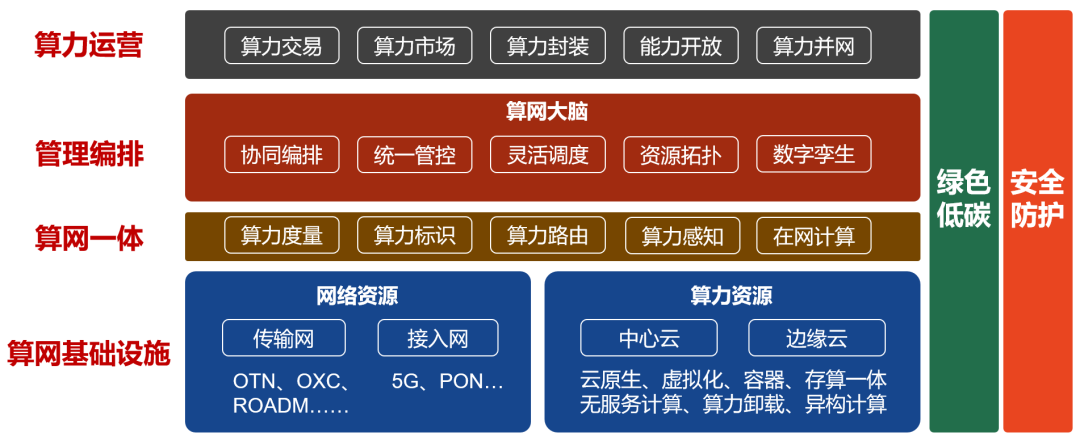
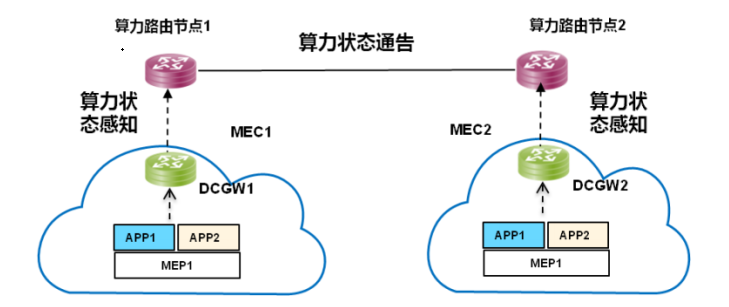
算力感知网络
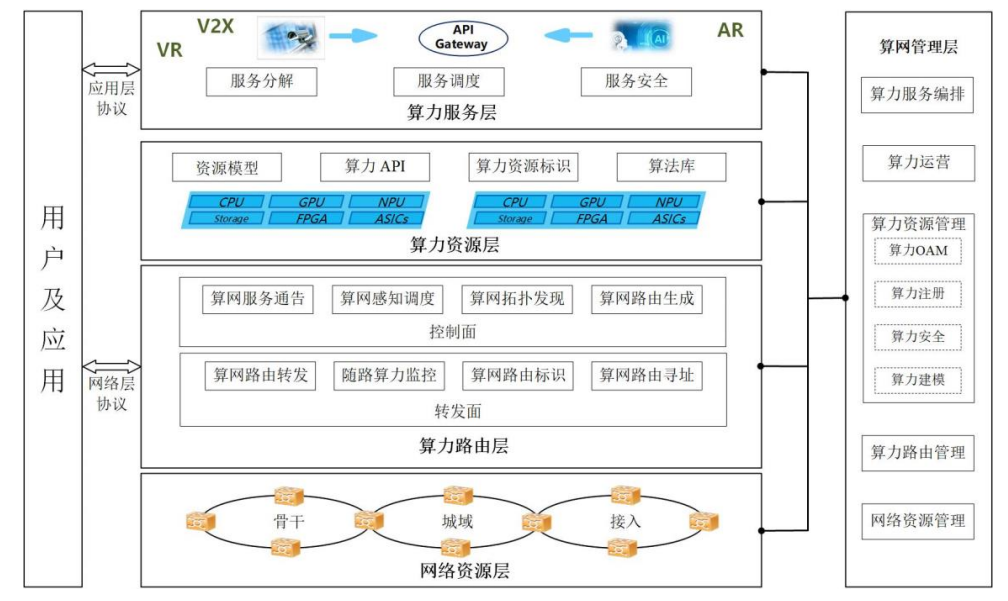
算力状态感知与通告
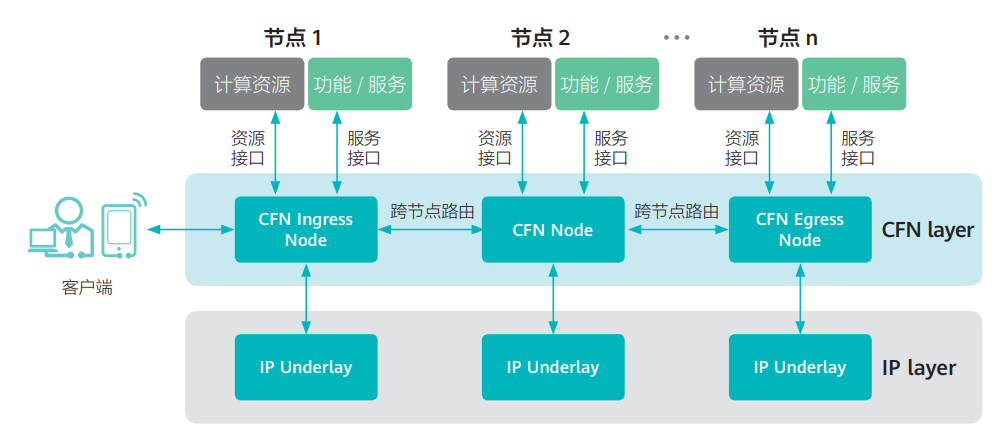
CFN技术架构
CFN广义上有时候会被用来指代整个算力网络。但是,在这里,CFN是一种分布式路由协议,在不同边缘云之间,按需进行着算力的调度和均衡。
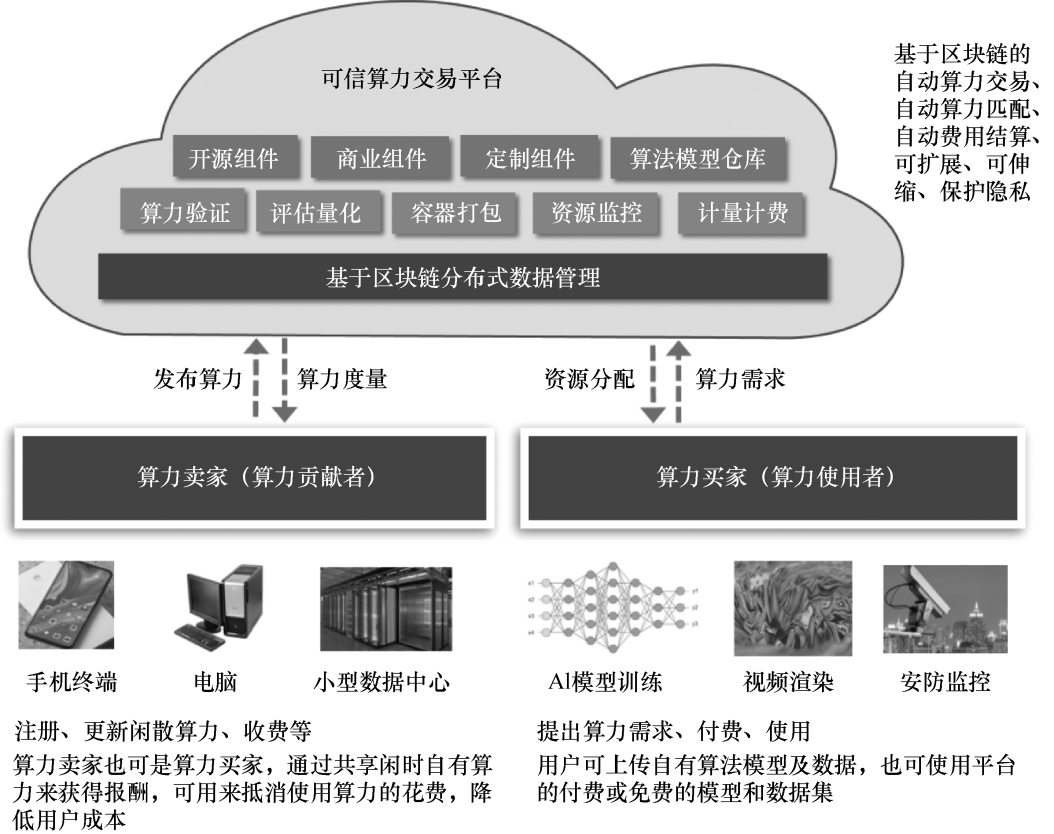
算力交易
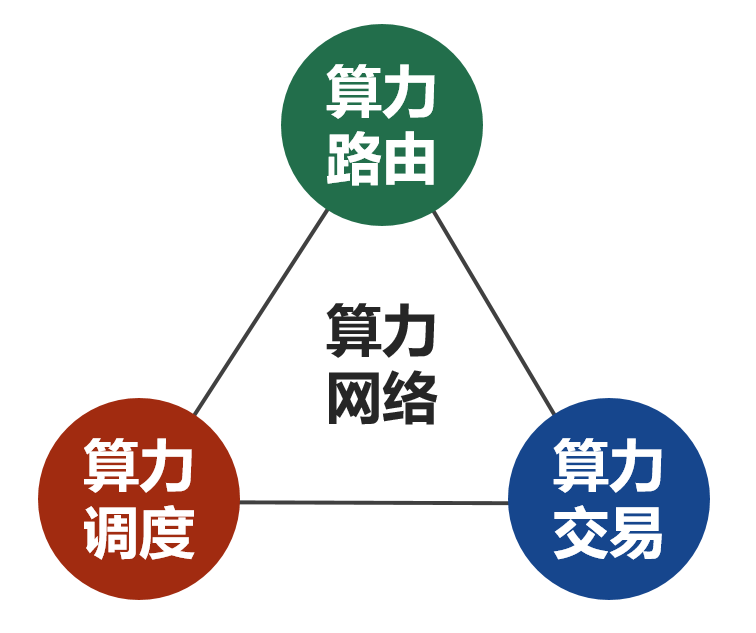
算力云网融合架构
五、结束语
算力中心就像一座数字化的“钢铁工厂”:
计算层是炉火熊熊的熔炉;
存储层是源源不断的矿石;
网络层是纵横交错的运输线。
三者相互配合,才让算力从“冷冰冰的芯片”变成“驱动社会的引擎”。
一句话总结:
算力中心不是单卡的堆叠,而是计算、存储、网络的系统性工程。
下一讲,我们将走进算力中心背后最隐蔽的挑战:能耗与冷却,为什么算力中心是“耗电怪兽”?